
Computer performance is characterized by the amount of useful work accomplished by a computer system compared to the time and resources used.
Depending on the context, good computer performance may involve one or more of the following:
- Short response time for a given piece of work
- High throughput (rate of processing work)
- Low utilization of computing resource(s)
- High availability of the computing system or application
- Fast (or highly compact) data compression and decompression
- High bandwidth / short data transmission time
Performance metrics
Computer performance metrics include availability, response time, channel capacity, latency, completion time, service time, bandwidth, throughput, relative efficiency, scalability, performance per watt, compression ratio, instruction path length and speed up. CPU benchmarks are available.
Aspect of software quality
Computer software performance, particularly software application response time, is an aspect of software quality that is important in human–computer interactions.
Technical and non-technical definitions
The performance of any computer system can be evaluated in measurable, technical terms, using one or more of the metrics listed above. This way the performance can be
- compared relative to other systems or the same system before/after changes
- defined in absolute terms, e.g. for fulfilling a contractual obligation
- defined in absolute terms, e.g. for fulfilling a contractual obligation
Whilst the above definition relates to a scientific, technical approach, the following definition given by Arnold Allen would be useful for a non-technical audience:
The word performance in computer performance means the same thing that performance means in other contexts, that is, it means "How well is the computer doing the work it is supposed to do?"
Technical performance metrics
There are a wide variety of technical performance metrics that indirectly affect overall computer performance.
Because there are too many programs to test a CPU's speed on all of them, benchmarks were developed. The most famous benchmarks are the SPECint and SPECfp benchmarks developed by Standard Performance Evaluation Corporation and the ConsumerMark benchmark developed by the Embedded Microprocessor Benchmark Consortium EEMBC.
Some important measurements include:
- Instructions per second – Most consumers pick a computer architecture (normally Intel IA32 architecture) to be able to run a large base of pre-existing, pre-compiled software. Being relatively uninformed on computer benchmarks, some of them pick a particular CPU based on operating frequency .
- FLOPS – The number of floating-point operations per second is often important in selecting computers for scientific computations.
- Performance per watt – System designers building parallel computers, such as Google, pick CPUs based on their speed per watt of power, because the cost of powering the CPU outweighs the cost of the CPU itself.
- Some system designers building parallel computers pick CPUs based on the speed per dollar.
- System designers building real-time computing systems want to guarantee worst-case response. That is easier to do when the CPU has low interrupt latency and when it has deterministic response.
- Computer programmers who program directly in assembly language want a CPU to support a full-featured instruction set.
- Low power – For systems with limited power sources (e.g. solar, batteries, human power).
- Small size or low weight - for portable embedded systems, systems for spacecraft.
- Environmental impact – Minimizing environmental impact of computers during manufacturing and recycling as well as during use. Reducing waste, reducing hazardous materials.
- Giga-updates per second - a measure of how frequently the RAM can be updated
Occasionally a CPU designer can find a way to make a CPU with better overall performance by improving one of these technical performance metrics without sacrificing any other (relevant) technical performance metric—for example, building the CPU out of better, faster transistors. However, sometimes pushing one technical performance metric to an extreme leads to a CPU with worse overall performance, because other important technical performance metrics were sacrificed to get one impressive-looking number—for example, the megahertz myth.
Performance Equation
The total amount of time (t) required to execute a particular benchmark program is
 , or equivalently
, or equivalently
where
- P = 1/t is "the performance" in terms of time-to-execute
- N is the number of instructions actually executed (the instruction path length). The code density of the instruction set strongly affects N. The value of N can either be determinedexactly by using an instruction set simulator (if available) or by estimation—itself based partly on estimated or actual frequency distribution of input variables and by examining generated machine code from an HLL compiler. It cannot be determined from the number of lines of HLL source code. N is not affected by other processes running on the same processor. The significant point here is that hardware normally does not keep track of (or at least make easily available) a value of N for executed programs. The value can therefore only be accurately determined by instruction set simulation, which is rarely practiced.
- f is the clock frequency in cycles per second.
- C=
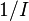 is the average cycles per instruction (CPI) for this benchmark.
is the average cycles per instruction (CPI) for this benchmark. - I=
 is the average instructions per cycle (IPC) for this benchmark.
is the average instructions per cycle (IPC) for this benchmark.
Even on one machine, a different compiler or the same compiler with different compiler optimization switches can change N and CPI—the benchmark executes faster if the new compiler can improve N or C without making the other worse, but often there is a trade-off between them—is it better, for example, to use a few complicated instructions that take a long time to execute, or to use instructions that execute very quickly, although it takes more of them to execute the benchmark?
A CPU designer is often required to implement a particular instruction set, and so cannot change N. Sometimes a designer focuses on improving performance by making significant improvements in f (with techniques such as deeper pipelines and faster caches), while (hopefully) not sacrificing too much C—leading to a speed-demon CPU design. Sometimes a designer focuses on improving performance by making significant improvements in CPI (with techniques such as out-of-order execution, superscalar CPUs, larger caches, caches with improved hit rates, improved branch prediction, speculative execution, etc.), while (hopefully) not sacrificing too much clock frequency—leading to a brainiac CPU design. For a given instruction set (and therefore fixed N) and semiconductor process, the maximum single-thread performance (1/t) requires a balance between brainiac techniques and speedracer techniques.







.jpg)